 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillGenBench: Benchmarking Skill Generation Pipelines for LLM Agents
May 18, 2026As LLM agents are increasingly built around reusable skills, a central challenge is no longer only whether agents can use provided skills, but whether they can generate correct, reusable, and executable skills from repositories and documents. Existing benchmarks primarily evaluate the efficacy of given skills or the ability of agents to solve downstream tasks from raw context, but they do not isolate skill generation itself as the object of study. We introduce SkillGenBench, a benchmark for evaluating skill generation pipelines under a unified and controlled protocol. In SkillGenBench, a generator receives raw corpora and produces standardized skill artifacts, which are then executed under fixed harnesses and assessed with unified evaluation procedures. The benchmark covers two generation regimes: task-conditioned generation, where a task-specific skill is synthesized after the task is revealed, and task-agnostic generation, where a reusable skill library must be distilled before downstream tasks are known. It also spans two complementary procedural sources: repository-grounded instances, where procedures are distributed across code, configuration, and scripts, and document-grounded instances, where procedures and constraints must be distilled from long-form text. We provide standardized task specifications, pinned environments, and evaluation protocols centered on deterministic execution-based checks, supplemented by auxiliary signals for diagnosis. Experiments across a range of skill-generation methods and backbones show substantial performance variation, highlight the difficulty of reusable skill distillation, and reveal distinct failure modes in skill generation from software repositories versus long-form documents. SkillGenBench establishes a reproducible testbed for studying skill generation as an independent research problem in agent systems.
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Jan 13, 2026While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.
Navi-plus: Managing Ambiguous GUI Navigation Tasks with Follow-up
Mar 31, 2025



Graphical user interfaces (GUI) automation agents are emerging as powerful tools, enabling humans to accomplish increasingly complex tasks on smart devices. However, users often inadvertently omit key information when conveying tasks, which hinders agent performance in the current agent paradigm that does not support immediate user intervention. To address this issue, we introduce a $\textbf{Self-Correction GUI Navigation}$ task that incorporates interactive information completion capabilities within GUI agents. We developed the $\textbf{Navi-plus}$ dataset with GUI follow-up question-answer pairs, alongside a $\textbf{Dual-Stream Trajectory Evaluation}$ method to benchmark this new capability. Our results show that agents equipped with the ability to ask GUI follow-up questions can fully recover their performance when faced with ambiguous user tasks.
SpiritSight Agent: Advanced GUI Agent with One Look
Mar 05, 2025Graphical User Interface (GUI) agents show amazing abilities in assisting human-computer interaction, automating human user's navigation on digital devices. An ideal GUI agent is expected to achieve high accuracy, low latency, and compatibility for different GUI platforms. Recent vision-based approaches have shown promise by leveraging advanced Vision Language Models (VLMs). While they generally meet the requirements of compatibility and low latency, these vision-based GUI agents tend to have low accuracy due to their limitations in element grounding. To address this issue, we propose $\textbf{SpiritSight}$, a vision-based, end-to-end GUI agent that excels in GUI navigation tasks across various GUI platforms. First, we create a multi-level, large-scale, high-quality GUI dataset called $\textbf{GUI-Lasagne}$ using scalable methods, empowering SpiritSight with robust GUI understanding and grounding capabilities. Second, we introduce the $\textbf{Universal Block Parsing (UBP)}$ method to resolve the ambiguity problem in dynamic high-resolution of visual inputs, further enhancing SpiritSight's ability to ground GUI objects. Through these efforts, SpiritSight agent outperforms other advanced methods on diverse GUI benchmarks, demonstrating its superior capability and compatibility in GUI navigation tasks. Models are available at $\href{https://huggingface.co/SenseLLM/SpiritSight-Agent-8B}{this\ URL}$.
Req2Lib: A Semantic Neural Model for Software Library Recommendation
May 24, 2020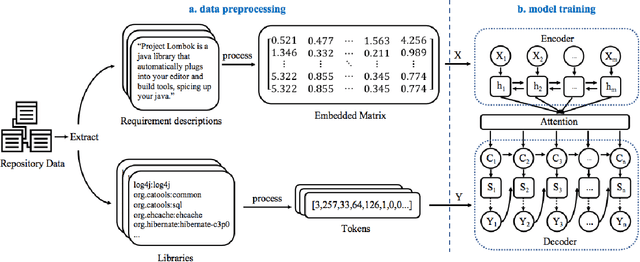

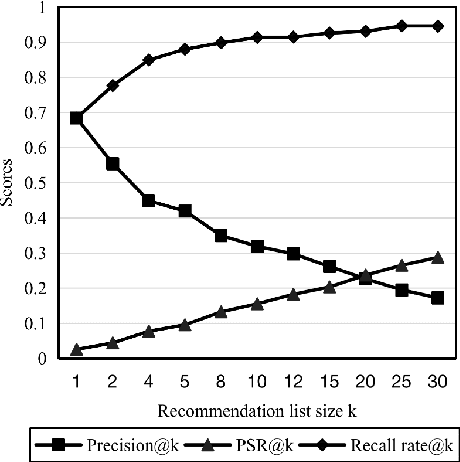
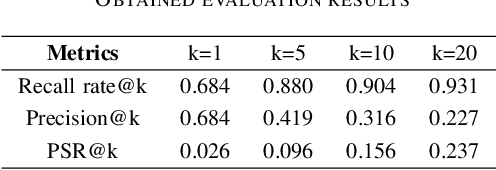
Third-party libraries are crucial to the development of software projects. To get suitable libraries, developers need to search through millions of libraries by filtering, evaluating, and comparing. The vast number of libraries places a barrier for programmers to locate appropriate ones. To help developers, researchers have proposed automated approaches to recommend libraries based on library usage pattern. However, these prior studies can not sufficiently match user requirements and suffer from cold-start problem. In this work, we would like to make recommendations based on requirement descriptions to avoid these problems. To this end, we propose a novel neural approach called Req2Lib which recommends libraries given descriptions of the project requirement. We use a Sequence-to-Sequence model to learn the library linked-usage information and semantic information of requirement descriptions in natural language. Besides, we apply a domain-specific pre-trained word2vec model for word embedding, which is trained over textual corpus from Stack Overflow posts. In the experiment, we train and evaluate the model with data from 5,625 java projects. Our preliminary evaluation demonstrates that Req2Lib can recommend libraries accurately.
* 5 pages